
When talking about the threat landscape for web applications, you might first think of SQL injections, cross-site scripting, and other well-known attacks. But, there are another vectors that often fly under the radar: HTTP headers. These headers are essential for web communication, yet they can be exploited for things like reconnaissance, authentication bypass, web cache poisoning, and server-side request forgery (SSRF). In this post, we’ll take a closer look at the hidden risks associated with HTTP headers.
What Are HTTP Headers?
HTTP headers are very simple at their core—they’re essential key-value components of web communication that pass additional metadata between clients’ (browsers) and servers. There are four main types of HTTP headers:
- Request Headers: Sent by the client to the server.
- Response Headers: Sent by the server back to the client.
- General Headers: Applied to both requests and responses.
- Entity Headers: Provide information about the body of the resource.
Generally speaking, the request and response headers are going to be the most important from an attacking POV. Let’s take a look at those a bit more in depth.
Request Headers
When your browser sends a request, it includes details about the request in its headers. Some common headers seen in such requests are:
- Host: Which could include an IP address, domain, and/or subdomain.
- Accept: This header indicates the media type the client can receive from the server. For example, it might accept any format, such as JSON, text, or HTML.
- User-Agent: Identified the web browser the client is using.
- Cache-Control: The browser’s caching behavior.
- Authorization: Which is used for the client’s credentials when trying to access a protected page
- Cookie: A unique token that ties to the user’s specific session they had.
Response Headers
After the client submits a request, the server responds. Once a response is successfully returned, you’ll notice that additional details are provided in the headers. Although HTTP responses often include more headers, that’s not always the case. Common response headers usually include the date and content-type.
- Date
- Content-Type
- Content Length
- Cache-Control
- Server
The Dangers of HTTP Headers
So, if these headers are necessary for the client and server to communicate, how can they be potentially dangerous?
Reconnaissance: Response Headers
One of the first steps with headers is gathering information. When reading HTTP responses, you can gain valuable insights into the technologies used by the application. There are many response headers that reveal this type of information, but here are a few that I found particularly useful:
- Server: This discloses the server the application is being hosted on (Ex. Cloudflare, Apache, Nginx, Microsoft-IIS).
- X-Powered-By: Can tell you what framework a site is running (Ex. WordPress, ExpressJS, PHP).
- X-Generator: Another great one when for looking for content management systems.
- Via: Discloses different proxies and load balancers (Ex. Cloudflare, F5).
- X-Backend-Server: While more uncommon, this can disclose an application’s backend server.
- X-Version: A custom header for whatever the respective technology is and it simply states the version of that technology.
- Set-Cookie: Will sometimes disclose certain languages depending on the session handling (So if you see PHPSESSID you know it’s PHP, and JSESSIONID would be Java).
Let’s take a look at some examples:
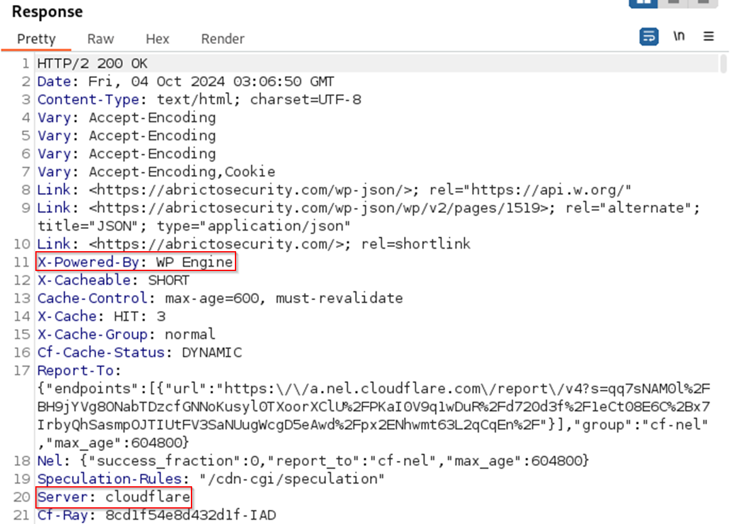
Upon a closer look at the response, the X-Powered-By header indicates that WordPress is running, and the Server header reveals that the server is behind Cloudflare.
Below is a response I got while testing a web application. We see that the Server header discloses that the application is running on Nginx 1.14.2.
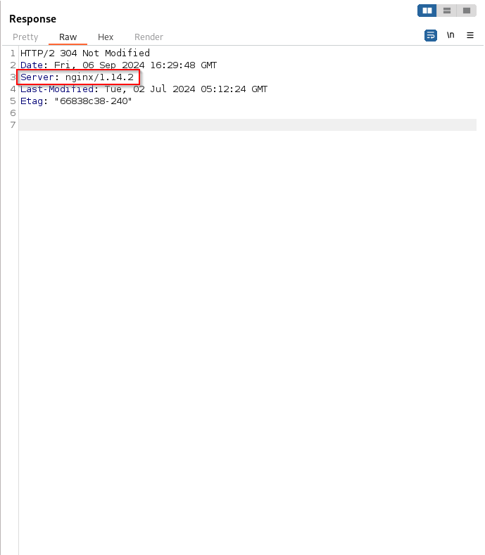
While there were no vulnerabilities for that version, a new vulnerability may be revealed tomorrow and a threat actor can gather that information. Also, be sure to check for the Strict-Transport-Security header. If it isn’t enabled, it opens the door for man-in-the-middle attacks since HTTPS isn’t being enforced.
Bypassing Captcha: IP-Spoofing
Another possible trick is bypassing CAPTCHA challenge responses. CAPTCHAs are in place to verify human input and limit login attempts. You can see how this could be an issue when testing for brute forcing or user enumeration. So I tried brute forcing the application with Intruder to see if I could identify the length returned when a CAPTCHA is triggered.

The normal content length is between 417 and 418, but when it drops to 410, I checked the response and found that I had received a CAPTCHA. I then let the attack run until I only received CAPTCHA responses, all of which were 410s at the bottom.
One way to bypass this is by using the X-Forwarded-For header, which identifies the originating IP address of a client when connecting through a proxy. When you send an initial request to the server, it logs the client’s IP address. However, by setting an arbitrary IP using the X-Forwarded-For header, you can trick the server into thinking that our IP is a proxy and that the originating IP is the one we set. In Burp, we can assign a payload to the user field we’re brute forcing and another payload to the X-Forwarded-For header, making it appear as though each request comes from a new address.
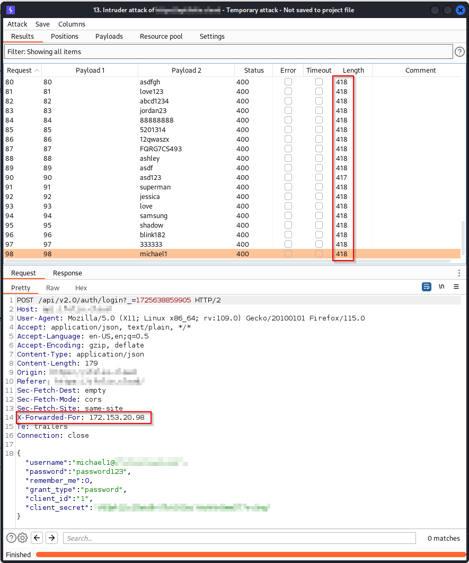
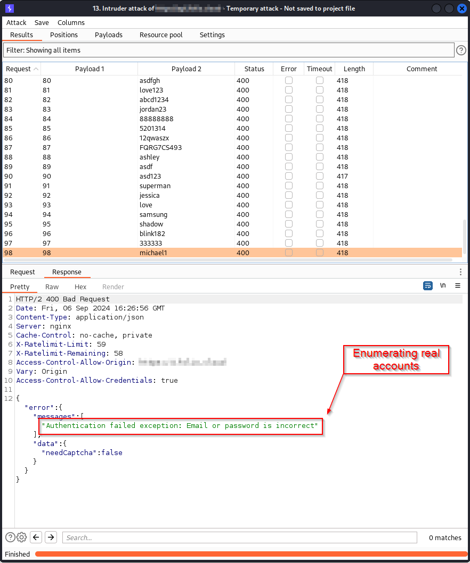
In this case, I created a Pitchfork Intruder attack to set multiple payloads—one to change the user and one to randomly assign an IP address for our newly added X-Forwarded-For header. After running the attack, it became clear that the content length for each request was consistent and there were no more 410 errors, effectively demonstrating that I had successfully bypassed the CAPTCHA. Note that X-Forwarded-For isn’t the only request header that can spoof your IP. A few alternatives include:
- X-Originating-IP
- X-Forwarded-Host
- Via
- True-Client-IP
Mitigating HTTP Header Attacks
As you’ve probably already figured out, none of these headers are inherently problematic—they’re built for specific purposes and serve certain use cases. However, there are some standard remediations that can address most issues related to HTTP headers, primarily by validating and sanitizing user input. In our examples, a good starting point is to avoid supporting host override headers. Depending on the framework used, additional headers might be supported by default. While there are certainly business applications for using headers to designate alternative IPs, it’s important to be aware of the security risk they present. Using headers like these allow for IP spoofing or host header overriding, which can facilitate brute force attacks and CAPTCHA bypasses.
There are many different flavors of HTTP header attacks, so staying up to date on the different varieties is critical to maintaining strong security for an organization. Portswigger Academy is an industry-standard resource for learning about attack vectors like HTTP headers, so check out their content for hands-on practice with these vulnerabilities here.
Warning: Please do not try these tactics and techniques on any domain without explicit permission from the domain owner. This information is provided solely for educational purposes, and Abricto Security is not responsible for any individuals who use these tactics and techniques in an unauthorized or malicious manner.